
本文摘譯自 Laura Hazard Owen 於2026年3月19日發表在尼曼新聞實驗室(Nieman Lab)的《ChatGPT, Claude, Gemini, and Grok are all bad at crediting news outlets, but ChatGPT is the worst (at least in this study)》。
加拿大研究人員詢問ChatGPT、Claude、Gemini、Grok四個AI模型的免費版與付費版有關加拿大的新聞報導,觀察它們會不會在答覆中註記新聞來源。
結果可能不會讓人感到驚訝:AI鮮少註記新聞來源,除非它們被要求這麼做,但有些還是做得比較好。
「這些AI模型系統性地吸收了加拿大的新聞內容。它們對國內政治、地方事務,以及當地報導視角的明確了解,是因為取得新聞內容,」麥基爾大學(McGill University)媒體、倫理及傳播學者 Taylor Owen 在其部落格寫道。「它們很少告訴你,資訊從哪來的。」
加拿大廣播公司(CBC)、《Globe and Mail》、《Toronto Star》、Postmedia、Metroland Media,以及加拿大通訊社(The Canadian Press)在2024年11月控告OpenAI侵害版權。這類案件在加拿大是首例,訴訟正在審理中。
Taylor Owen也是媒體、科技及民主中心的創始主任。他與麥基爾大學助理教授 Aengus Bridgman 說明了他們的研究(粗體是作者畫的重點):
我們在未啟動網路搜尋的情況下,用2267篇真實的加拿大新聞報導(英法文都有)測試四個主要的AI模型,結果出現相同模式。四個模型都展現出對加拿大時事的廣泛了解,符合已吸收加拿大新聞報導的看法。在訓練期間,約74%的回覆展示出對事件至少部分了解,但在這些回覆中,約92%完全沒提供資訊來源。
當我們使用網路搜尋,並透過各公司的應用程式介面(API)測試140篇獨特文章,每個模型生成的回覆,都涵蓋足夠的原始內容,讓許多使用者幾乎不用再去看原文章。這些模型通常會連結到加拿大新聞網站,約52%的回覆至少有一個加拿大的網址,但只有約28%的回覆,會明確給出加拿大的資訊來源。連結提供回到資料原始來源的途徑,但使用者在看(AI模型)回覆時,不太會注意自己正在看哪家媒體的報導。
提及率高,但標示率不高。Gemini和Claude各約有81%、72%的回覆涵蓋原文獨特資訊(特定事件、提及人物、重要發現),但Gemini有註記來源的回覆僅約6%。Grok約有59%的回覆涵蓋原文獨特資訊,其中僅約7%有註記來源。ChatGPT是最獲廣泛使用的模型之一,其約54%的回覆涵蓋原文獨特資訊,但幾乎從未註記原始新聞來源。
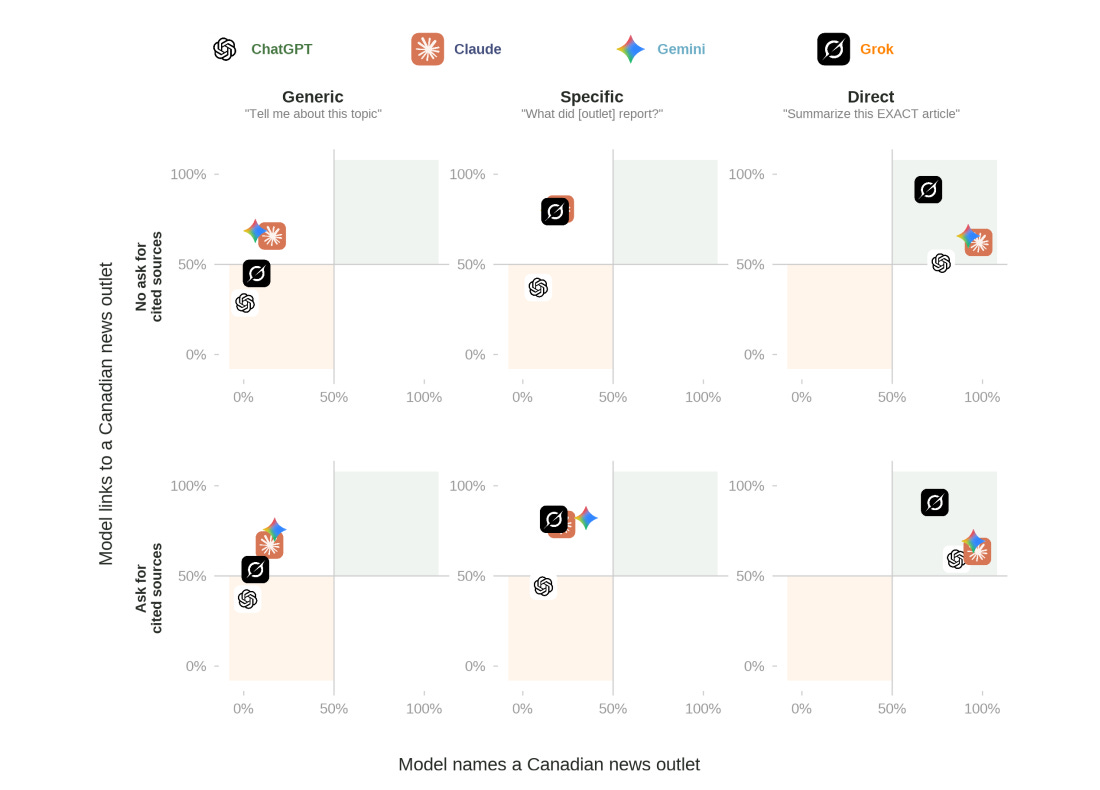
在沒要求的情況下,ChatGPT幾乎不會註記資訊來源,在這次測試樣本中,標示率僅約1%;Claude則約有16%。
當被明確要求註記來源時,所有AI模型都做得更好,不過大部分使用者不會這樣要求。
在最佳條件下(直接標明媒體及明確要求註記來源),所有模型的標示率都變高。這四種模型在大部分回覆中都標明媒體:Claude(97%)、Gemini(95%)、ChatGPT(86%)和Grok(74%)。連結率也增加:Grok(91%)、Gemini(69%)、Claude(64%)和ChatGPT(59%)。有意義地註記來源在技術上是可行的,不過大多數使用者並不會要求標明媒體或資料來源,因此一般情況下所得到的結果,才是真正形塑新聞市場的使用經驗。
研究人員發現,當AI模型註記資料來源,往往是使用者已熟悉的來源,有付費牆和較小型地方媒體的內容較少被註記為來源,就算是原創內容。
我寄了電子郵件詢問研究報告作者:若必須選出哪個AI模型的新聞視角最「正確」,會是哪個呢?Aengus Bridgman給了有趣的回答,我在這全文公布,我想我們的讀者可能也會覺得有趣。註:AI模型的「截止日」(cutoff)是完成訓練的日子,「截止日前」的文章是在模型訓練期間發布,「截止日後」即指(完成訓練)之後發布。
他寫道:
這真的是很難的問題,因為每個模型的表現不同:
Claude引用加拿大媒體媒體的內容頻率最高(約61%,ChatGPT和Gemini分別為8%、3%),它對不知道的事,會坦承告知,而非幻想編造。付費版中,只約有37%的回覆實質提到「截止日前」的報導,這是因它選擇拒答。但換到的是,當有網路存取權限時,很高比例(約68%)會覆述付費內容。
ChatGPT有最好的使用介面,讓最近的新聞露出(內嵌引用、可點擊連結)。可是付費版有最糟的幻覺表現,其中88%不準確,且約87%的「截止日後」回覆是看起來可信,但它不可能知道的內容。
Gemini在有網路存取權限時,回覆最快且涵蓋最多原文獨特資訊(約81%),但幾乎不會在回覆內容中標示加拿大資訊來源(有標示的約2%至8%)。因此,它在隱藏資訊來源的同時,最有效地取代了使用者造訪資訊來源的需求。
Grok是僅憑訓練資料(無須啟動網路搜尋),就能讓加拿大媒體露出的最強模型。但在「截止日後」的內容中,有很大的幻覺成分(約89%涉及它不應該知道的議題,約84%不準確)。
最令我驚訝的是這現象的複雜度和各公司嘗試的各種方法。每家公司都有各自的設定,這些決策導致不同的產出及行為,這或多或少展示責任感(像是拒絕編造或重出原本內容)以及價值轉移(對資訊來源的提及程度和/或對付費牆的處理方式)的差異 。這些重要差異顯示出在該領域自我管理能力的不健全。
AI新聞檢查(Ai News Audit)報告由麥基爾大學媒體、科技及民主中心發布。你可在這裡閱讀全文,包括提供加拿大公共政策圈有關AI的建議。