
自2022年ChatGPT問世以來,生成式人工智慧(Generative AI)在全球掀起熱潮,應用場景迅速擴展,新聞領域亦不例外。從AI驅動的虛擬主播(數字人主播)、輔助寫作與剪輯轉錄、生成新聞示意圖像,到分析龐大數據,AI已廣泛應用於新聞產製的各個環節。近來,更有專為新聞編輯室打造的AI顧問工具出現,旨在推廣新聞從業人員「負責任地使用AI」。
2023年8月,法新社(AFP)、美聯社(AP)、歐洲新聞圖片社(EPA)、歐洲出版商委員會(EPC)、《今日美國》(USA Today)母公司Gannett、Getty Images等多家媒體組織聯合發表公開信,呼籲制定生成式AI模型的規範與負責任的發展原則。AP也在不久後推出一套正式的AI指導方針,成為首家針對新聞編輯室內部發布AI使用規範的主要新聞組織。
在中文新聞圈,台灣的中央通訊社(CNA)與公共電視(PTS)於2023年9月分別公布AI使用規範與準則;《報導者》在2024年7月公開 AI 使用守則。在中國,國營的中央廣播電視總台(CMG)在2024年3月也出台了帶有政治指導方針的《人工智能使用規範(試行)》,強調不管技術如何發展,遵循導向正確始終是首要原則,並「堅持社會主義核心價值觀」。
英國《金融時報》(FT)中文版《FT中文網》在新聞產製與傳播過程中廣泛應用 AI,不過鮮少公開其使用細節,規範亦存在於組織內部、並未公開。《FT中文網》已推出專屬聊天機器人,並在語音讀報、電子報製作、生成圖像與專欄編譯等環節常態化導入AI。在新聞前線見證AI浪潮、也在北京清大新傳學院授課的《FT中文網》總編輯王丰接受《田間》專訪,分享他們如何在擁抱AI科技的同時堅守新聞專業,為讀者提供更具價值的服務。

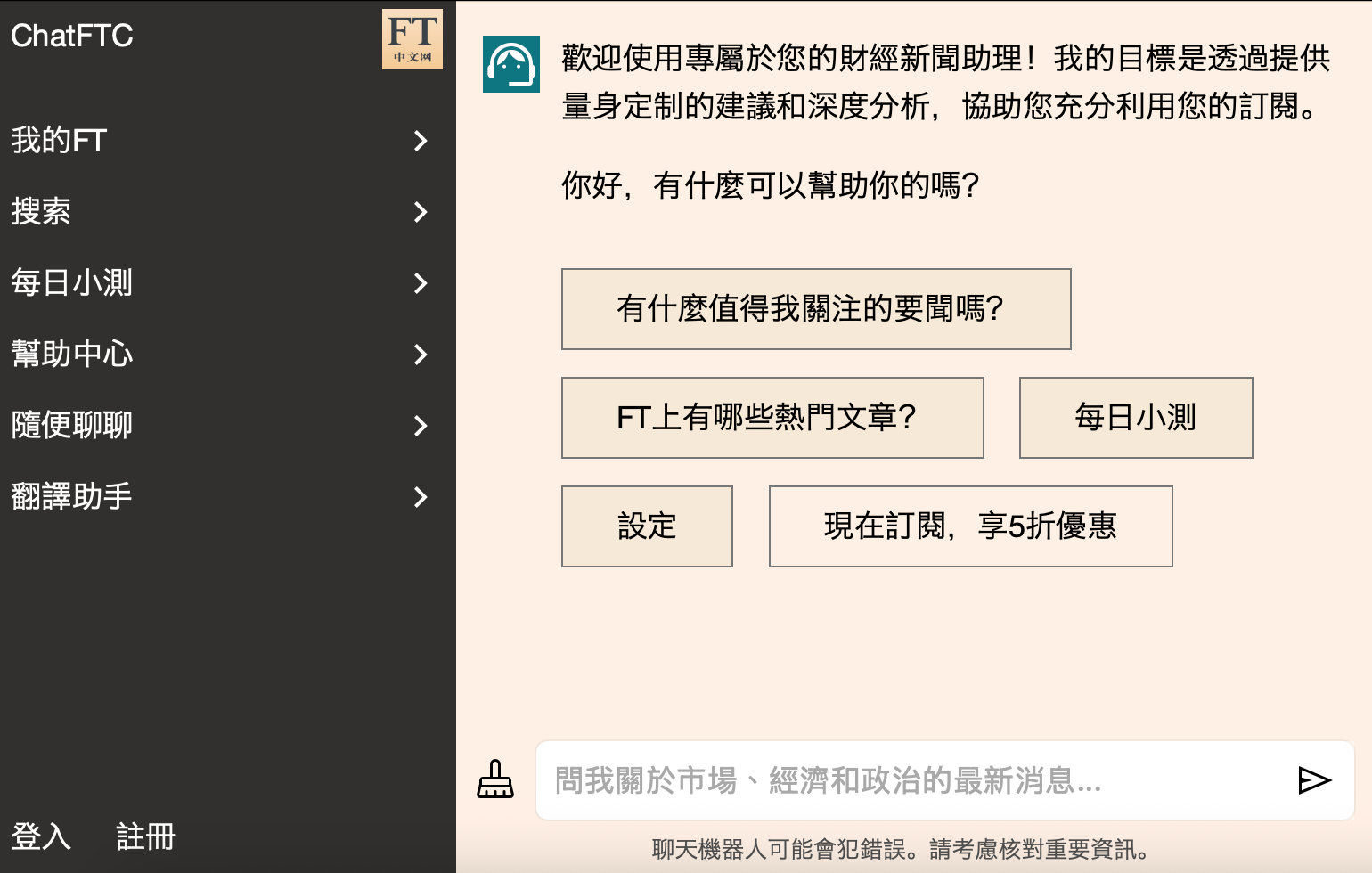
田間(以下簡稱田):《FT中文網》有許多AI應用,作為讀者端,首先注意到您們開發出名字與ChatGPT相似的專屬聊天機器人ChatFTC,扮演用戶的AI財經新聞助理。能否分享開發過程?訓練資料為何?目前使用率和用戶反饋如何?
王丰(以下簡稱王):這不是中文網原創的東西,這是FT(Financial Times)總部那邊上百位技術團隊做出的產品,技術團隊已經對它進行了預訓練,基於ChatGPT的框架,但用FT的新聞內容做訓練。然後在這基礎上,我們(FT中文網)又把它拿過來,用《FT中文網》的中文內容又把它訓練一遍。
它的特殊之處在於你可以發問,比如說在FT的新聞報導裡面,關於這個主題,過去一年還有什麼樣相關的報導,有哪些事實、哪些數據,給我一個timeline(時間軸),給我一個更長遠的背景介紹...... 就是讓普通讀者閱讀一篇新聞之外,能有更深度的、而且是基於FT NewsArchive(新聞資料庫)的體驗。
但在過程中,恐怕仍舊難以百分之百地避免hallucination(AI幻覺)。因為至少對我們編輯來說,這個聊天機器人仍舊是個比較黑箱的工具。技術團隊開發後交給我們,但他是如何開發、如何訓練、對新聞資料庫的access(權限)到什麼程度,我們編輯也不是很清楚。
所以我們也向讀者說明,這仍舊是一個experimental product(實驗性產品),我們希望它能提升你的體驗,但仍不能百分百保證它的準確性,如果真的需要引用作為可靠的工作指導、或者是研究的指導,建議最終還是要以FT發表的文章為準。
田:FT總部是何時開始投入AI相關工具的研發?《FT中文網》有時間差嗎?
王:FT現在和OpenAI有合作協議,不過2023年FT還沒有跟OpenAI合作時,我們到總部參加每年例行高管會議,當時公司就要求所有參會高管在現場註冊Anthropic帳號、註冊一個Claude,逼著高管們立刻認識到現在AI已經進展到了什麼程度。
作為FT的高管,我們第一次認識到了大語言模型已經可以在文字上有如此突飛猛進的進展。大概在同一時間,倫敦總部那邊就已經開始跟這些AI公司進行談判,包括Anthropic、OpenAI,然後在2023年到2024年進行了很深入的開發。中文網本身是同步進行,總部那邊開發好的東西,我們立刻就可以拿過來用,蠻及時的。
田:目前FT用戶對AI財經新聞助理「ChatFTC」的使用情形如何?
王:當然我們並不能看到讀者們都用它在做什麼。但技術團隊可以看到多少人在用、用掉了多少流量、每個讀者用的頻率大概在哪。然後他們會定期把這些數據反饋給編輯團隊。
但目前更多是一個有趣的、新奇的噱頭,使用率不是很高。因為有個很嚴重的問題是,中國大陸是沒法訪問ChatGPT的。就連我本人平時在香港,都得用VPN(虛擬私有網路)才能訪問ChatGPT。我們在大陸的讀者如果想要使用這個功能,他就要翻牆。而且大陸現在翻牆很難,這還得是訂閱戶才能用,所以這有好幾層限制,也許只有那些非常tech savvy(懂科技)、本身可以順利翻牆的那些讀者會使用。
田:《FT中文網》的讀者群如何分布?
王:《FT中文網》的主要市場,首先中國大陸佔絕對大頭,85%的讀者在中國大陸,5%到8%的讀者在香港,然後陸續排下去是台灣、新加坡,然後是北美、歐洲、英國、澳大利亞、加拿大的華人讀者。《FT中文網》最初就是面向中國大陸開發的中文內容產品。20年前我們剛創立的時候,是想把英文內容翻譯成中文,更多的給這些在中國大陸、接受國際資訊很受限制的人群來使用。
田:若是從讀者導向出發,例如聊天機器人這類的產品服務有無考慮串接Deepseek?團隊對中國開發的AI工具使用經驗如何?
王:這就涉及到AI大模型的地緣政治監管問題。因為我們母公司(FT)仍舊是家英國公司,它跟OpenAI已經達成合作協議,公司認可它足夠安全。所以公司目前政策是,當要應用AI時,主要就只使用OpenAI的產品。再加上中國和英國、和歐洲之間有歐盟GDPR法規(General Data Protection Regulation,一般資料保護規則)的數據跨境流動問題,所以我們中文網即使要想跟DeepSeek合作,估計母公司那邊也沒法通過。
我們員工目前使用上是沒有很嚴格的限制,但例如在transcribe(轉譯)採訪內容時,如果有敏感信息能不能上傳到科大訊飛(iFlytek)的服務器?如果同事們有顧慮,我們就會一起討論。我的建議是,如果有敏感的信息,就不要用科大訊飛,就用人工方式自己轉譯。但好在我們多數做的內容,還都沒有上升到如此之敏感的層面。
DeepSeek、騰訊元寶和豆包,我和同事都用得挺多的。我們認為DeepSeek最大的問題就是幻想非常嚴重,一本正經地瞎編內容或撒謊,這樣的情況挺常見,頻率會比Perplexity或ChatGPT高很多。所以我個人很少用DeepSeek做和採訪或內容相關的工作。只是它中文用起來還是更舒服些,所以有時候我用它改寫新聞標題或做摘要,但是我會重新讀一遍,確保這裡面沒有問題。
母公司最近開始做問卷,要了解每個人都在使用哪些AI工具,我猜想下一步是要制定策略,防止可能出現的數據或是隱私問題。We are making up the rules as we go.(我們是一邊摸索,一邊建立規則。)內部的管理制度至今仍不斷在更新。

田:FT總公司目前有一份關於使用AI的準則或規範嗎?
王:總公司有些基本的行為準則,並且每年定期培訓,要求做內部考試。但具體如何執行,現在似乎很難,所有公司幾乎都還沒有能夠做到說要監控每個員工的每一項工作。
在日常工作中如何具體適用這些原則,就靠每個人來做自我裁決。如果有不確定的地方,就跟主管聊一聊,由主管指導。如果主管也決定不了的話,就上升到legal counsel(法律顧問)或者是in-house lawyer(公司內部律師)來諮詢。
我會跟我的同事們聊這些話題,也會在團隊內部分享我個人使用AI的經驗。最基本的就是,即便是AI生成的一切內容,你仍要對它的準確性百分之百負責,要去核實AI告訴你的一切。
現在多數的人還都是在不斷地探索怎麼樣使用AI,更多的人還沒有想到,怎麼樣保證AI做出來的能符合一切職業、道德、法律等各方面的守則,還沒有想到那麼長遠,能確保內容百分百準確就已經很不容易。We are still in the very early stages.(我們現在只是剛起步。)
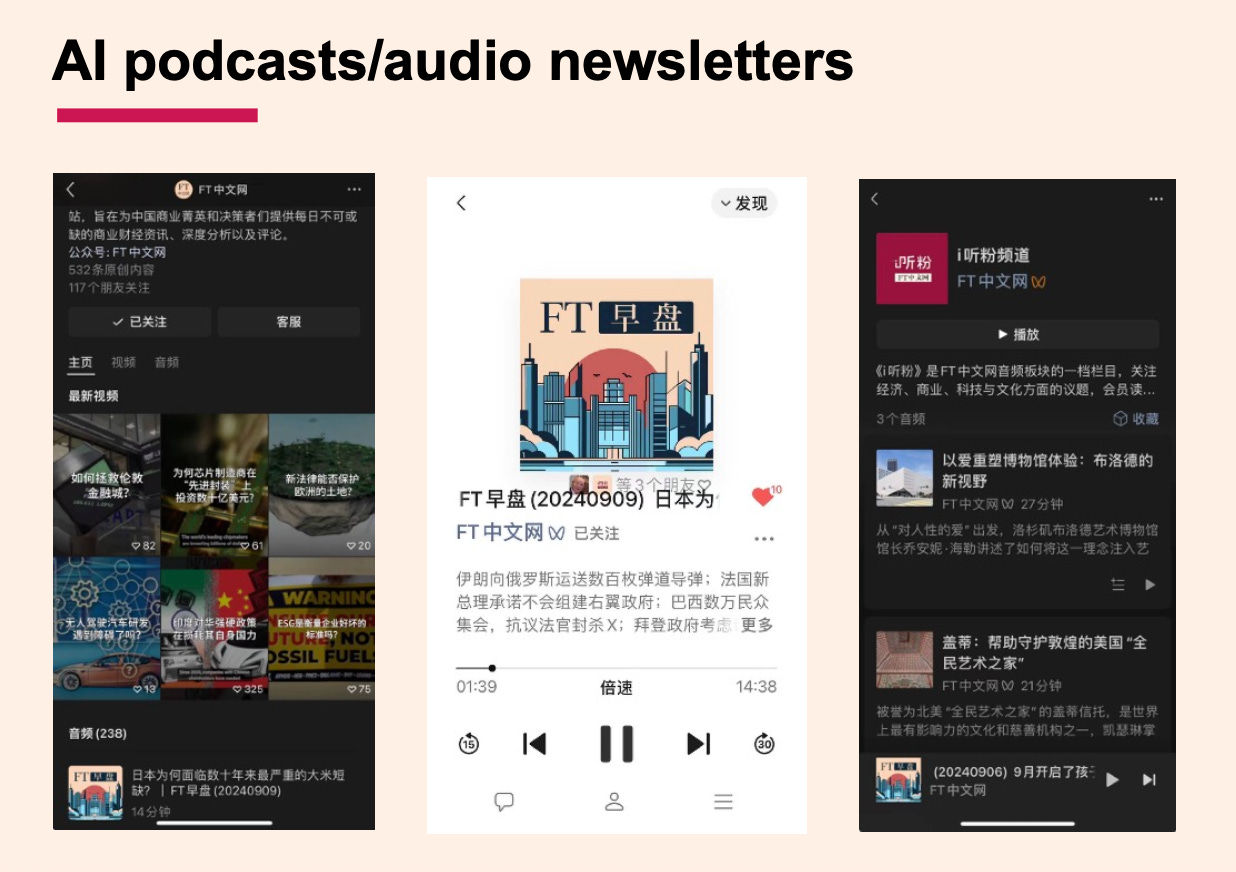
田:除了ChatFTC之外,FT也在Podcast製作上使用AI?
王:目前許多是experiment(實驗),還沒有真正推出。例如大家都覺得NotebookLM能夠做一個podcast這件事很有意思,但很多人用了幾天之後就發現,因為不能控制它如何討論問題,所以最終出來的效果,仍舊不足以作為一個新聞產品呈現給讀者,更多是給我們內部思考。許多這些AI工具,我們時常可以看看它好玩,但還沒有想好究竟怎麼用它。
關於AI應用新聞產品,我們FT中文現在已經大量做的是用AI做語音摘要。比如說用AI將2000字的文章摘要成200字,然後用AI聲音讀出來,每天通過微信發給讀者。這可以讓一些開車的人、通勤的人,通過耳機能聽這篇文章。
我覺得中國讀者非常能夠接受新鮮事物,AI語音summary,讀者接受程度還挺高。但是我曾在個人公號上試過AI podcast(播客),一旦我告訴讀者說,這是由兩個AI生成來對話,大家一旦知道是AI做的,興趣就不是很高了。所以重點還是人的附加價值。
目前《FT中文網》使用AI工具的做法,更多是周邊性的、尤其在內容傳播的層面二次加工。在生產原創內容時,還是遵循傳統。
田:記者和編輯把關,對自己產生的內容負責,《FT中文網》有沒有因使用AI出現過問題?
王:我們目前沒有出現scandal(醜聞)或嚴重的事實性錯誤。我們內部呢,一般編輯的原創內容,會經過至少two pairs of eyes(至少經過兩人審核)。當然相較很多傳統媒體是三人或四人核稿,這流程可能會有疏漏,但目前還沒有發現特別明顯的問題。
目前FT中文網使用AI工具的做法,更多是周邊性的、尤其在內容傳播的層面使用AI。在生產原創內容時,還是遵循傳統,記者去跟受訪者做面對面採訪,或是視頻採訪,全文錄下來,可以寫成文字、做成視頻、做成音頻,這是非常傳統的內容製作過程。
在這過程中可以怎麼樣使用AI?比如說當我們去採訪一位專家,但對他研究的領域非常外行,如何能夠問出更好的問題?這是我們比較常用到AI的場景。採訪時,仍舊是我們自己和專家面對面,受訪者告訴我們的東西,仍舊需要自己記下來、寫下來。
如果用AI協助轉譯,回頭還是需要對內容做核查。在這整個過程中,已經可以基本避免絕大部分AI可能出現的不準確或是幻想的問題,AI是輔助角色。
下一步當我們把文字寫出來、或把視頻製作出來以後,我們可以用AI進行加工,把它做成一篇newsletter(電子報)或者podcast。也就是基於傳統新聞流程產生的、能夠確保準確性的內容,進行進一步的加工或傳播時使用AI。
田:這代表新聞專業仍有存在價值?如何看待現在網路上有多而氾濫的AIGC(AI生成內容)?
王:AI寫的稿子肯定不能直接發表,甚至AI寫的稿子哪怕經過幾輪編輯的改寫,我們都並不一定有信心它能夠有準確的新聞判斷。
我們要做的是,盡量確保在新聞工作的核心流程中,尤其是具有原創性、對內容的準確、客觀和新聞性,要有人類的判斷。能確保這個,那麼產生出來的內容,實際上跟傳統新聞工作流程產生出來的內容,差別並不是很大。只是利用AI做二次或三次加工,在傳播過程中使用AI提高效率。所以我們對可能出現的不準確,就不那麼擔憂。
現在在YouTube、TikTok上面,已經能看到大量氾濫的AIGC。這之中似乎很多是娛樂或休閒類內容,這類資訊含量較低,與前AIGC時代社交媒體上大量的clickbait(釣魚標題)內容沒有太大區別,除了浪費人們大量時間,造成brainrot(大腦腐蝕)似乎也沒有更加直接的傷害。
但介於娛樂與資訊、新聞之間的內容,如果大量用AI製作未經核實、包含虛假、不全面信息,而且用AI大量製造傳播,就可能造成很大的危害,更可以被政治、商業、犯罪勢力利用操作misinformation或disinformation campaign(錯假資訊宣傳),危害比社交媒體時代成倍放大,非常值得警惕。包括中國在內的一些國家已經立法要求社媒和資訊平台明確標註AI生成或AI輔助生成的內容,我覺得有助於減輕劣質AIGC內容帶來的危害。
田:您建議新聞工作者應具備哪些AI能力?您最推薦的AI工具有哪些?
王:我個人最喜歡的是Perplexity,功能特別強大,免費版就已經可以查到相當多內容。處理大量資料時,NotebookLM比較好用,它能夠確保沒有編造,目前大概幾十頁的投影片、幾十萬字的書稿或學術論文,就目前能用到的場景,已經很夠了。
另外是Google的Pinpoint,我還在學習,還沒有找到一個很好的機會使用。我對它的理解是,例如像Panama Papers(巴拿馬文件)這種規模的資料,當你拿到這種規模的數據,需要進行梳理、需要在裡面尋找線索時適合使用,但是我們現在沒有機會能夠拿到這種巨量數據來試驗這個工具。
還有一個是Manus,這是我自己目前唯一付費使用的AI工具,它可以執行非常複雜的工作。我近期寫了一本新聞學的教科書,基於我過去兩年在清華大學、香港大學兼職教課的內容。但我不是自己去寫的。兩年的課程總共有大概600到700頁的PowerPoint,我把所有的這些材料上傳給AI,利用工具去寫。
我試過很多個工具,包括ChatGPT、DeepSeek、Manus...... 經過幾個月的試錯,我研究出來一個流程。我先讓Manus清晰地按照這些投影片內容做出章節,等於是做出一本書的骨架,下一步再用ChatchGPT的Deep Research功能核實、補充內容,把邏輯銜接起來寫成文字。我研究出來這個流程後,就能比較有效率把這本書寫出來。
我給學生兩個基本原則。一是我鼓勵你們使用AI,甚至要求他們使用AI。因為如果你們不使用AI,到你們畢業時,所有其他人都在使用AI,如果你還沒有用的話,就不具備競爭力了。二是你要對所有一切內容負同樣責任,不論是不是由AI產生。如果AI產生了hallucination、bias(偏見)或inaccuracy(不準確),你要能夠發現它並進行改正。
那麼靠什麼能夠發現它並進行改正呢?這仍需要傳統的新聞學教育。20年前的新聞學是什麼,今天同樣都要學,你才能夠知道AI什麼是做不對的、什麼是對的,不然你都沒有判斷能力。

田:學生使用AI的比例有無上限或規範?
王:我沒有設置比例上限。因為用一個工具去判斷這篇文章有70%的AI本身就是非常愚蠢的事情。第一,今天所謂的AI偵測工具,本身就是很不可靠的,它們永遠落後於那些大語言模型。
然後現在很多學生更頭疼一件事情是,即使這篇文章都是我自己做研究寫出來的,仍舊被認為40%的AI,學生們更多時間是在擔憂,自己寫出來的東西,怎麼能不被認為是AI作弊的結果。這完全是counterintuitive(違反直覺)的事情。所以我覺得(限制使用)是完全沒有意義的。
我認為不管用什麼工具,文章寫得漂亮、那就很好,只要你能夠確保它是很確實,不會被我找出問題,我就會給高分。
田:下一代的記者、新聞系學生使用AI和社群的使用增加,對從事新聞行業帶來什麼優勢?
王:我在清華的課是傳統的新聞課程,英語新聞寫作和商業新聞寫作。但是我每天都在說,這堂課你們覺得可以什麼地方使用AI,能讓你更快一點?或是這個數據對比同一個公司兩年的財務報表,你用哪個工具能幫你更準確?可以說我每天都在用AI工具,重新詮釋傳統的新聞實操的工作流程。
AI對於像我們這樣母語非英語的記者或學生,在學習新聞寫作的過程中,掌握寫作風格和正確的文法能幫助很多。這兩年學生文字水平提高很多,給我的內容都很好,但我不確定的是,這裡邊有多少是自己學到的,還有多少是通過AI跨越了捷徑。但我可以確定,等他們畢業時,所有人都在用AI,如果你不用,在市場上就缺乏競爭力了。
我能確定的是,我要教你傳統的新聞是怎麼做的,什麼是對的,什麼是錯的,什麼是好的。即使不是自己寫出來,至少要有判斷力,用AI幫助進一步的加工,我覺得都是可以接受的。在過程中最好能夠加入你個人的智慧跟觀點,最終就是產生的內容要準確、符合傳統新聞的標準,內容是好的、有新意的,能夠持續地產生出來,那就足夠好。
田:我很好奇,華文媒體和西方媒體相比,您覺得在面對AI這件事情的態度上有何不同?
王:至少據我所接觸的,中國大陸的新聞工作者和讀者,大家的心態開放程度比較高。當然我們所要做到的就是確保所有人都意識到這裡面存在的風險,包括道德、法律、隱私和數據安全方面的問題。但中國大家整體來說,比起西方接受程度都會更多一些。
在FT內部,我會更加謹慎一些。因為FT很多資深的記者跟編輯,可能不會那麼容易接受這些。公司很多資深的記者和編輯們仍舊很難接受,公司內部仍舊在勸說大家對AI有更好的接受程度。
田:您個人對新科技的應用充滿好奇心、感興趣也具有實驗精神,FT中文網團隊中其他人對於AI的態度普遍是怎麼樣的?
王:我自己的確是對這比較感興趣。我做了26年記者,包括通訊社、報紙和雜誌的記者,但有大概20年是做編輯,更多時間是在做這些機構的網站。所以我從來都是相當於一個internet native(網路原住民),一直在做relaunch a website(重啓網站)、build a new functionality to this website(為媒體網站添加新功能)、add more social media features to this website(為該網站添加更多社交媒體功能)。也許因為這樣,接受程度比較高。
就使用AI而言,一定程度上,我對學生的影響比較多,對同事的影響呢,也只能說:「我想出來一個流程,會讓你的工作變簡單」,這樣的建議。5年前COVID剛開始的時候,公司進行了大規模裁員,人手一下減少了很多,但是工作跟原來一樣多,每個人忽然面臨很大壓力。
在這個過程中,我就幫他們想,比如說如何用AI來加快轉譯速度。我把流程初步想好,跟大家一起討論,讓他們認識到,這對你是有現實幫助的,不然一天就要工作15個小時了。更多是用這種辦法,讓大家來buy in(接受)。我並沒有逼每個人,沒有設立使用AI的KPI或什麼時候要開始用,只要他們知道用原始的方式做事很累,用AI可以提高效能,那這不是很好?
田:在報導中國相關議題時,《FT中文網》如何拿捏平衡,保持專業與深度,又能確保順利發表?您曾遇到需要格外謹慎的題材嗎?
王:《FT中文網》的宗旨是以商業資訊服務中國的商業與專業讀者,內容定位是以經濟金融科技資訊為主,這一定位能夠幫助我們化解在中國市場可能遇到的多數法律、政策、監管方面的問題。另外,我們也非常重視展現中國視角,邀請大量中國內地及大中華區的專家學者、專業人士為我們撰寫原創評論和分析,也有助於我們平衡中國與西方話語,為我們的讀者提供更專業、中立、平衡的資訊和深度分析。
田:美國財經週刊《巴倫》(Barron’s)與中國財經科技媒體《鈦媒體》合作推出的「巴倫中文網」於6月28日上線。您如何評價《巴倫》此時推出中文內容的策略?
王:巴倫周刊與FT有競爭關係,同樣《巴倫中文網》也會與《FT中文網》有內容和商業方面的競爭。在近年來許多國際媒體中文網站關停或撤出中國市場的背景下,我們積極看待其他國際媒體開設中文網站,服務中國讀者。